
Spis treści
Czytasz teraz:
JavaScript a SEO – jak poprawnie zoptymalizować dynamiczne strony pod Google?
Zamknij
Tworzenie stron internetowych wymaga użycia wielu technologii i rozwiązań. Szybki rozwój branży oraz rosnące oczekiwania użytkowników, powodują konieczność odnajdywania nowych sposobów na prezentację treści. Wygląd witryn i sposób renderowania ich zawartości niestety nie zawsze idzie w parze z oczekiwaniami Google’a, który przez długi czas miał problemy z renderowaniem stron opartych na JavaScripcie. Do dzisiaj pozycjonowanie witryn JS wymaga specjalnego podejścia…
JavaScript – teoria
Strona internetowa ma postać kodu, który odczytywany jest przez przeglądarki i renderowany we wskazany sposób. Kolejne elementy witryny dodawane są poprzez znaczniki HTML:
Wygląd strony wymaga dodania dodatkowego pliku, napisanego w css-ie. Style najczęściej są umieszczone w pliku style.css.

Witryny zbudowane w oparciu o HTML i CSS są stosunkowo proste. Tworzenie rozbudowanych serwisów wymaga zastosowania rozwiązań bardziej zaawansowanych technicznie, pozwalających na dynamiczne dostarczanie treści, renderowanie HTML-a na poziomie serwera oraz przetwarzania informacji od użytkowników i zapisywanie ich w bazie danych. Zastosowanie dodatkowych technologii pozwala także na uatrakcyjnienie formy przekazania informacji na stronie.
(Dalszą część artykułu znajdziesz pod formularzem)
Wypełnij formularz i odbierz wycenę
Zapoznamy się z Twoim biznesem i przygotujemy indywidualną ofertę cenową na optymalny dla Ciebie mix marketingowy. Zupełnie za darmo.
Administratorem Twoich danych osobowych jest Verseo spółka z ograniczoną odpowiedzialnością z siedzibą w Poznaniu, przy ul. Węglowej 1/3.
O Verseo
Siedziba Spółki znajduje się w Poznaniu. Spółka jest wpisana do rejestru przedsiębiorców prowadzonego przez Sąd Rejonowy Poznań – Nowe Miasto i Wilda w Poznaniu, Wydział VIII Gospodarczy Krajowego Rejestru Sądowego pod numerem KRS: 0000910174, NIP: 7773257986. Możesz skontaktować się z nami listownie na podany wyżej adres lub e-mailem na adres: ochronadanych@verseo.pl
Masz prawo do:
- dostępu do swoich danych,
- sprostowania swoich danych,
- żądania usunięcia danych,
- ograniczenia przetwarzania,
- wniesienia sprzeciwu co do przetwarzania danych osobowych,
- przenoszenia danych osobowych,
- cofnięcia zgody.
Jeśli uważasz, że przetwarzamy Twoje dane niezgodnie z wymogami prawnymi masz prawo wnieść skargę do organu nadzorczego – Prezesa Urzędu Ochrony Danych Osobowych.
Twoje dane przetwarzamy w celu:
- obsługi Twojego zapytania, na podstawie art. 6 ust. 1 lit. b ogólnego rozporządzenia o ochronie danych osobowych (RODO);
- marketingowym polegającym na promocji naszych towarów i usług oraz nas samych w związku z udzieloną przez Ciebie zgodą, na podstawie art. 6 ust. 1 lit. a RODO;
- zabezpieczenia lub dochodzenia ewentualnych roszczeń w związku z naszym uzasadnionym interesem, na podstawie art. 6 ust. 1 lit. f. RODO.
Podanie przez Ciebie danych jest dobrowolne. Przy czym, bez ich podania nie będziesz mógł wysłać wiadomości do nas, a my nie będziemy mogli Tobie udzielić odpowiedzieć.
Twoje dane możemy przekazywać zaufanym odbiorcom:
- dostawcom narzędzi do: analityki ruchu na stronie, wysyłki informacji marketingowych.
- podmiotom zajmującym się hostingiem (przechowywaniem) strony oraz danych osobowych.
Twoje dane będziemy przetwarzać przez czas:
- niezbędny do zrealizowania określonego celu, w którym zostały zebrane, a po jego upływie przez okres niezbędny do zabezpieczenia lub dochodzenia ewentualnych roszczeń
- w przypadku przetwarzanie danych na podstawie zgody do czasu jej odwołania. Odwołanie przez Ciebie zgody nie wpływa na zgodność z prawem przetwarzania przed wycofaniem zgody.
Nie przetwarzamy danych osobowych w sposób, który wiązałby się z podejmowaniem wyłącznie zautomatyzowanych decyzji co do Twojej osoby. Więcej informacji dotyczących przetwarzania danych osobowych zawarliśmy w Polityce prywatności.
Budowanie dynamicznych aplikacji możliwe jest dzięki szerokiej gamie języków programowania, poszerzających funkcjonalności witryn internetowych. W ostatnich latach jednym z najpopularniejszych języków programowania jest JavaScript. Potwierdza to m.in. raport “The 2020 State of the Octoverse”, podsumowujący działania deweloperów w obrębie platformy GitHub.
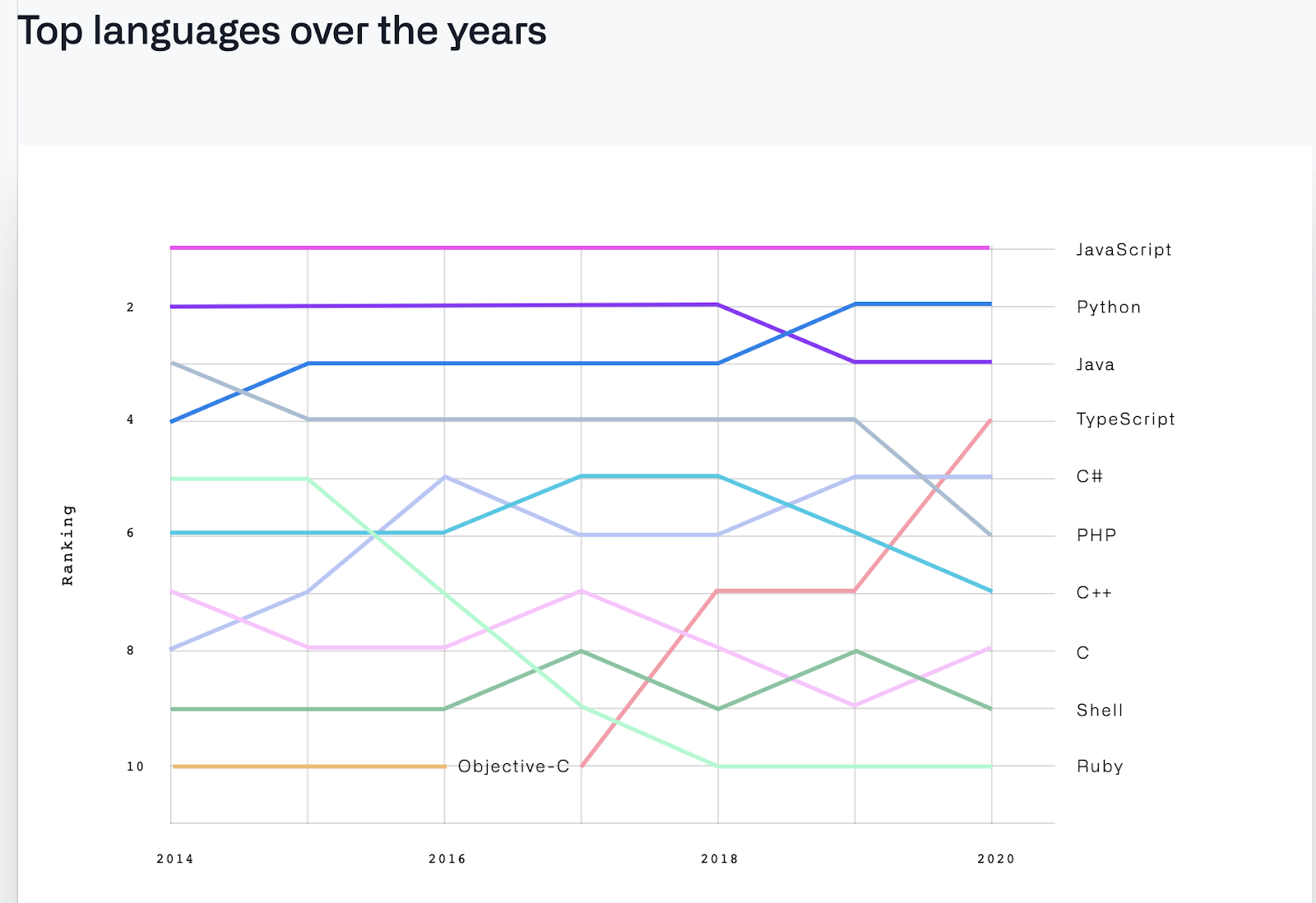
(źródło: https://octoverse.github.com/)
JavaScript powstał pod koniec 1995 roku. Początkowo wykorzystywano go przede wszystkim do walidacji informacji wprowadzanych przez użytkownika (np. poprawność adresu mailowego w formularzu), dzisiaj pozwala na budowanie dynamicznych witryn. Dzięki skryptom strona “żyje” i reaguje na działania użytkownika – galeria grafik staje się interaktywna, pop-upy można zamknąć, a Google Analytics zbiera informacje na temat ruchu na stronie. JS odpowiedzialny jest także za inne elementy, bez których witryny internetowe wydają się nie spełniać współczesnych standardów:
- infinite scroll (czyli ładowanie kolejnych elementów, np. produktów bez przeładowywania strony),
- komentarze i oceny,
- wewnętrzne linkowanie,
- listy “the best” produktów lub artykułów.
Wybór JavaScriptu jako technologii o którą będzie oparta strona, pozwala na umieszczanie na niej elementów pobranych z zewnętrznych źródeł, chociażby API Google Maps lub API z portali społecznościowych.
Kod JavaScript znajduje się w pliku zapisanym jako .js (najczęściej script.js) – odnośnik do niego wstawia się w sekcji head strony lub bezpośrednio przed końcowym tagiem body (co jest zalecane). Niektóre fragmenty kodu umieszcza się jednak także bezpośrednio między html-owymi tagami (np. skrypt odpowiadający za Google Analytics), co umożliwia wykonanie się kodu (tj. pojawienie się konkretnego działania na stronie) zanim wczytana zostanie cała struktura HTML i CSS. Tego typu zabiegi niestety mają zazwyczaj negatywny wpływ na prędkość renderowania się witryny – warto więc posługiwać się tą opcją w ograniczonym zakresie.
W obrębie witryn, które zbudowane są według tego standardu, na początku wczytywana jest struktura HTML, która następnie jest uzupełniana o kod CSS. Na końcu wykonywany jest kod JS, zgodnie z kolejnością kolejnych elementów znajdujących się w pliku – z góry do dołu.
O tym, z jakich technologii korzysta strona internetowa, dowiedzieć się można m.in. z pomocą narzędzi typu https://www.netcraft.com/. Podglądanie ewentualnych błędów skryptu JS umożliwiają narzędzia wbudowane w przeglądarkę, np. DevTools w Chrome (prawy przycisk myszy -> Inspect), zakładka “Console”.
Client-side rendering czy server-side rendering?
JavaScript jest specyficznym językiem – wykonywać go można po stronie serwera (server-side) oraz po stronie przeglądarki (client-side). Obie opcje pozwalają na zbudowanie nowoczesnej aplikacji internetowej, atrakcyjnej dla użytkowników i robotów sieciowych.
Server-side rendering (SSR) to najpopularniejsza metoda wyświetlania stron internetowych. Przeglądarka wysyła informację do serwera, który przesyła odpowiedź w formie wyrenderowanego HTML-a, a ten wyświetlany jest na naszym ekranie. Prędkość odpowiedzi uzależniona jest od m.in.:
- połączenia internetowego,
- lokalizacji serwera (odległości od komputera, z którego zostało wysłane zapytanie),
- ruchu na danej stronie (ile zapytań jest wysyłanych w tym samym czasie),
- od optymalizacji witryny, np. cache i możliwości przechowywania części plików w pamięci podręcznej przeglądarki).
Każde kolejne kliknięcie powoduje konieczność przeładowania strony – serwer wysyła odpowiedź zawierającą HTML, zawierającą te same elementy, co poprzednia podstrona.
Client-side Rendering pozwala na renderowanie odpowiedzi po stronie klienta – najczęściej przeglądarki internetowej. W tym przypadku, w odpowiedzi na request przeglądarki, serwer wysyła plik JavaScriptowy, który jest odpowiedzialny za stworzenie struktury HTML i dodanie do niego contentu. W przypadku przejścia na kolejną podstronę, witryna nie musi zostać przeładowana – JS pobiera z serwera niezbędną treść i uzupełnia nią wyrenderowany wcześniej szkielet HTML. Odpowiedź serwera jest szybsza, a łącze internetowe mniej obciążone.
Client-side rendering jest zazwyczaj szybszy, jednak ze względu na konieczność wykonania się całego kodu JS, pierwsze wczytanie witryny może być dłuższe niż przy SSR. Renderowanie po stronie klienta – renderowanie widoku tylko dla danej przeglądarki, może powodować problemy ze skutecznym pozycjonowaniem witryny.
Google vs. JS – wyboista droga do sukcesu
Możliwości, jakie daje kod JavaScriptowy, miały znaczący wpływ na jego popularność. JS pozwala m.in. na tworzenie dynamicznych stron, bazujących na szablonie napisanym w html+css, uzupełnionymi danymi pobranymi np. z baz danych. Co więcej, potencjał jaki wiąże się z tym językiem, daje możliwość manipulowania szablonami, tworzenia dodatkowych elementów i renderowanie strony “w locie” – w trakcie wykonywania się programu. Na tej zasadzie w pierwszych latach swojego istnienia działał m.in. kreator stron Wix – renderował witryny na podstawie kodu JS.
Niestety, jak już wspomniałam wyżej, takie rozwiązanie nie sprzyja zajmowaniu wysokich pozycji w wyszukiwarce Google. Roboty sieciowe spod znaku firmy z Mountain View przez wiele lat nie potrafiły dobrze analizować stron JavaScriptowych, co z kolei przekładało się na brak możliwości rywalizowania w SERP-ach. W ostatnich latach Google deklarował poprawę swoich zdolności w tym zakresie, jednak skuteczność rozczytania plików z kodem nie zawsze jest zadowalająca.
Pozycjonowanie stron JavaScript wymaga przede wszystkim zapoznania się z tym, jak Googlebot przetwarza kod JS. W przypadku statycznych stron schemat działania robota jest dość prosty:

Google sprawdza czy może wejść na dany adres (dostęp dla robotów może być zablokowany w pliku robots.txt lub tag w <head>), następnie pobiera dane strony – strukturę HTML i równocześnie sprawdza co znajduje się na wszystkich linkach znajdujących się w kodzie. Następnie odczytywane są pliki z CSS-em i strona przekazywana jest do zaindeksowania.
W przypadku stron JavaScript ten proces wygląda inaczej:

Jak widać na załączonym diagramie droga, jaką musi przebyć Googlebot jest znacznie bardziej skomplikowana. Po pobraniu pliku HTML, ściąga kod CSS i JS, który jest niezbędny do wyrenderowania strony. Następnie uzupełnia go zasobami pobranymi z zewnętrznych źródeł (jeśli takie są) i renderuje stronę. Wygląd strony i niezbędne elementy jej struktury zawarte są w kodzie JS, który pozwala na manipulowanie poszczególnymi fragmentami i dostosowywanie ich do potrzeb użytkownika.
Renderowanie kodu przed jego indeksowaniem może się wydłużać i Google nie gwarantuje uzyskania wszystkich informacji, które pragnęliśmy zawrzeć na stronie. Ma to związek m.in. z liczbą adresów URL, jakie robot skanuje w ciągu dnia – tzw. “crawl budget”. Uwzględnienie potrzeb Googlebota pozwala na jego efektywne pełzanie pod stronie, które przekłada się na widoczność witryny w wynikach wyszukiwania.
Rozrysowanie ścieżki Googlebota daje jasny pogląd na poziom skomplikowania pozycjonowania stron opartych na JavaScripcie. Niestety, nie informuje o ryzykach i problemach, jakie mogą pojawić się w trakcie kolejnych kroków. Przyjrzyjmy się im bliżej…
Może Ci się spodobać
- Pięć wskazówek do optymalizacji technicznej strony internetowej
- Minifikacja CSS i JS – jak odchudzony kod przyspiesza ładowanie strony
- Budżet crawlowania – dlaczego Google nie zawsze widzi całą Twoją stronę
- Strony statyczne vs dynamiczne – różnice w kontekście wydajności i SEO
Strony JS – co widzi Google?
Strony internetowe oparte w dużej mierze na kodzie JavaScriptowym od zawsze stanowiły spore wyzwanie dla robotów Google. Poziom ich indeksacji rośnie, jednak wciąż nie są tak duże, jak byśmy mogli sobie tego życzyć.
Google renderuje strony inaczej niż przeciętna przeglądarka, w inny też sposób korzysta ze strony niż użytkownik. Algorytm działania skupia się przede wszystkim na elementach, które są konieczne do wyrenderowania witryny. Te, które uzna za mniej istotne, może pomijać i w efekcie nie uwzględnić ich podczas indeksowania. Jest to problematyczne zwłaszcza w sytuacji, gdy pod tymi fragmentami znajduje się treść strony, która miała docelowo stać się przepustką do wysokich pozycji w wynikach wyszukiwania. Szczególnie narażone na pozostanie niewidzialnym są dane uzależnione od plików cookies – jeżeli content serwowany jest na ich podstawie, Google zapewne do niego nie dotrze. Dodatkowe kwestie to także prędkość z jaką wykonuje się kod – zła optymalizacja może przedłużać cały proces i spowodować porzucenie go przez robota.
Drugi problem to brak aktywności Googlebota podczas wizyty na stronie – Google nie scrolluje strony, nie klika tam, gdzie użytkownik i blokuje automatyczne odtwarzanie wideo. W przeciwieństwie do innych gości na stronie może nie dotrzeć do wszystkich przygotowanych treści i nie mieć pełnego obrazu witryny.
Informacje o tym, jak Google renderuje naszą witrynę uzyskać można przy pomocy Testu optymalizacji mobilnej (https://search.google.com/test/mobile-friendly?hl=pl). Po wprowadzeniu adresu, Mobile Test pobierze wskazaną przez nas podstronę i zwróci informacje dotyczące procesu renderowania – w tym także komunikaty o problemach. Po prawej stronie pojawi się również podgląd wyrenderowanej strony.
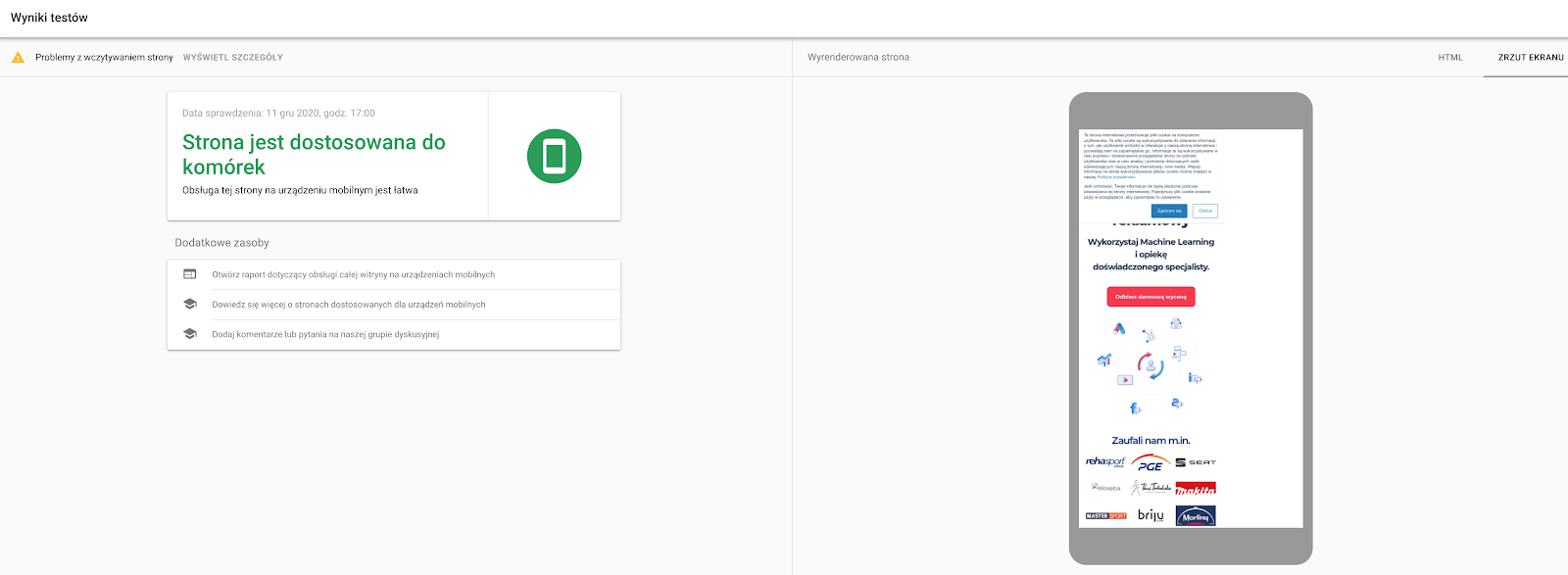
Informacje na temat problematycznych elementów dostępne są pod przyciskiem “Problemy z wczytywaniem strony”.
Stronę sprawdzić można również w Google Search Console – “Sprawdzenie adresu URL”. Obie formy kontroli sposobu renderowania witryn pozwalają na uzyskanie danych niezbędnych do wprowadzenia ewentualnych zmian i poprawienia indeksacji witryny opartej o JS.
Single Page Apps – React, Vue.js oraz inne frameworki
Duży nacisk na prędkość dostarczania danych oraz popularność technologii stosowanych w aplikacjach mobilnych spowodowało wzrost popularności witryn typu Single Page Apps. Tego typu witryna posiada jeden plik html, który wykorzystywany jest do renderowania kolejnych podstron. Treści pobierane są dynamiczne z serwera, poprzez requesty JS.
SPA są szybkie i dobrze odbierane przez użytkowników. W trakcie wizyty przeglądarka pobiera wszystkie statyczne elementy, pozostała zawartość doczytywana jest w trakcie wizyty. Przejścia między kolejnymi fragmentami strony są dynamiczne – omijamy moment przeładowywania się strony. Z pozycji użytkownika wygląda to tak samo jak w przypadku bardziej tradycyjnych stron – np. linki w menu mają znajomą formę <a href=”/o-nas”>O nas</a>, jednak po kliknięciu w nie, przeglądarka nie pobiera danych z kolejnego pliku html – de facto pozostaje w podstawowym index.html, a treści “o-nas” pobierane są z bazy danych i renderowane z pomocą JS.
Do budowania Single Page Apps wykorzystuje się model AJAX, który pozwala na komunikację z serwerem w sposób asynchroniczny, który nie wymaga odświeżania dokumentu przy każdej interakcji użytkownika z witryną. Strony budowane są z pomocą frameworków, które Wikipedia określa jako “szkielet do budowy aplikacji”. Framework odpowiada za strukturę aplikacji, mechanizm działania, komponenty i niezbędne biblioteki. Do najpopularniejszych frameworków zalicza się m.in. React, który wykorzystywany jest do budowania interfejsów aplikacji. Często stosowane są także Vue.js oraz Ember.js. Framework rozwijany i promowany przez Google nosi nazwę “Angular”. Najpopularniejsze frameworki pozwalają na renderowanie witryn po stronie serwera (co jest zalecane z perspektywy łatwego pełzania po stronie przez Googlebota) oraz uwzględniają wymagania przeglądarek mobilnych.
Jak już wspomniałam wcześniej, Google nie zawsze radzi sobie z tego typu witrynami, co sprawia że pozycjonowanie niektórych Single Page App opartych na JavaScripcie bez odpowiedniej optymalizacji może być niemożliwe. Dobrym przykładem jest tu witryna http://www.histography.io/. Strona dostarcza sporo informacji historycznych (zaciągniętych z Wikipedii), jednak Google nie widzi jej potencjału:

W indeksie Google znajduje się strona główna oraz dwa przypadkowe PDF-y. Roboty sieciowe nie mają też dostępu do treści strony głównej i widzi tylko to:
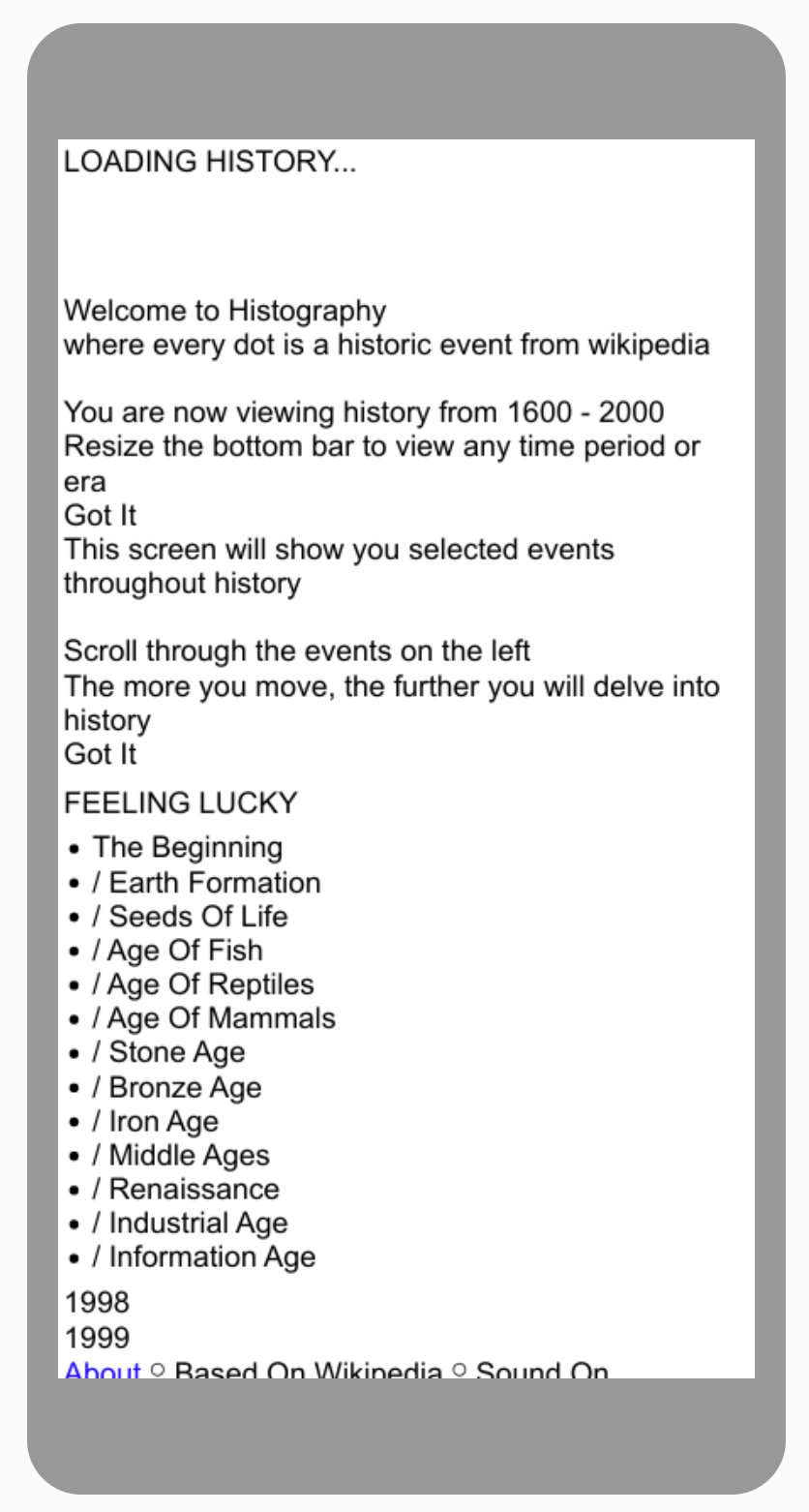
O ile w przypadku witryny tego typu brak obecności w Google nie jest aż tak znaczący, o tyle w przypadku sklepu może znacząco wpływać na zainteresowanie klientów. Strony stworzone przy pomocy popularnych frameworków – React, Vue.js czy Angular, pozwalają na wprowadzenie elementów niezbędnych do zaistnienia w indeksie Google oraz serwują content w sposób pozwalający na konkurowanie w zakresie pozycji.
Pozycjonowanie i optymalizacja stron JS
Rozwiązania, których zastosowanie umożliwia kod JavaScript, mają pozytywny wpływ na prędkości witryny i jej odbiór przez użytkowników. Wyświetlenie strony przez potencjalnych klientów to jednak jedynie połowa sukcesu – większość z nich trafia pod nasz adres URL dopiero w momencie, w którym znajdzie go w wynikach wyszukiwania Google.
Optymalizacja stron internetowych z dużą ilością kodu JavaScript wymaga wprowadzenia zmian, które dla statycznych stron wydają się być oczywiste.
Dostęp dla robotów sieciowych
Jak wspomniałam wcześniej, Googlebot w pierwszej kolejności sprawdzi czy napotkany przez niego adres URL jest dla niego dostępny. Dotyczy to wszystkich zasobów znajdujących się w jego obrębie – w tym plików JS oraz CSS. Renderowanie stron JS przez Google wymaga pełnego dostępu do kodu, należy zatem unikania blokowania tych zasobów w pliku robots.txt.
Adresy URL
Jednym z problemów, na które można napotkać podczas optymalizacji witryny opartych w dużej mierze na JS, jest brak “tradycyjnych” odnośników do kolejnych podstron serwisu. Googlebot skupia się jedynie na linkach umieszczonych w atrybucie href, w tagu <a>.
Innym problemem związanym z adresami URL typowymi dla witryn z dużą ilością JS jest też korzystanie z adresów z “#”. Krzyżyk pozwala uniknąć konieczności scrollowania dokumentu i przenieść się bezpośrednio do wybranego fragmentu.
Jednym z rozwiązań w obrębie tych problemów jest skorzystanie z HTML5 History API. Pozwala na manipulację historią przeglądarki – np. zmianę adresu w pasku adresowym przeglądarki i zmianę treści, bez konieczności przeładowywania podstrony. API jest wbudowane w większość frameworków (m.in. React Router), co znacznie ułatwia budowanie stron, które pozwalają na pozycjonowanie w Google. Uwaga – tego typu rozwiązania nie będą skuteczne przy starych wersjach przeglądarek.
Wśród innych problemów z adresami URL warto zaznaczyć też dość spory potencjał na tworzenie się duplikatów stron, z adresami różniącymi się wielkością liter lub slashem na końcu. Ten problem rozwiązuje umieszczenie w sekcji <head> linka kanonicznego. Zawarty w nich adres będzie jednoznaczną informacją dla Google.
Sitemap.xml
Elementem, który znacznie ułatwia indeksowanie witryny, są pliki zawierające odnośniki do wszystkich adresów w obrębie domeny – mapy strony. Mapa strony to lista, na które powinny zostać zawarte wszystkie adresy, na które chcemy zaprosić bota.
Przekierowania oraz problem pozornych błędy 404
Jednym z istotnych elementów procesu optymalizacji strony jest wyłapywanie niedziałających adresów URL i kierowanie ich na nowe, poprawne. Przekierowania 301, 302 itd. wykonuje się w obrębie serwera. W przypadku Single Page App nie ma jednak możliwości zastosowania tego rozwiązania. Jak sugeruje Centrum Pomocy Google i, jak potwierdzają testy wykonane przez Search Engine Land, odpowiednie zastosowanie kodu JS będzie działać w podobny sposób.
Przekierowanie JS pozwoli na przekierowanie adresu na kolejną podstronę, nie da jednak odpowiedzi typowej dla przekierowań wykonanych na serwerze. Z punktu widzenia obecności w wynikach wyszukiwania nie jest to jednak problem. Przekierowanie skutecznie zastępuje stary adres nowym, który może piąć się dalej w rankingu.

window.location.replace zastępuje bieżący dokument tym, który umieszczony jest pod wskazany adresem. Adres oraz zawartość pierwotnego dokumentu nie zostanie zachowana w pamięci podręcznej. Tego typu zabieg to kolejny przykład na skuteczne zastosowanie wspomnianego wcześniej HTML5 History API.
Wśród innych istotnych dla robotów sieciowych kodów odpowiedzi serwera, wymienić warto także 404, “Not Found”. W przypadku stron JS (chociaż ten problem występuje również w przypadku źle skonfigurowanych stron statycznych), brak dokumentu pod wskazanym adresem będzie odczytywany przez serwer jako poprawna odpowiedź 200. W efekcie, w indeksie wyszukiwarki mogą znaleźć się nieistniejące adresy, niezawierające treści. W celu zniwelowania tego problemu i poinformowania robotów o konieczności zajrzenia na inne podstrony, warto uzupełnić kod o fragment pozwalający na uzyskanie pożądanej odpowiedzi z serwera. Przykład z Google Search Central:

Dodatkowo zaleca się również zablokowanie robotom możliwość indeksowania danego adresu poprzez dodanie do tagu robots dyrektywy “noindex”.
Opóźnienie wczytywania
Prędkość strony to jeden z elementów rzutujących na dobrą widoczność witryny. Optymalna prędkość dostarczania treści i innych elementów contentowych pozwala na wygodne korzystanie z witryny bez nadmiernego obciążania połączenia internetowego użytkownika. Jednym ze skuteczniejszych rozwiązań jest lazy loading – opóźnienie wczytywania się niektórych elementów witryny. Uwaga – niepoprawna implementacja może zablokować dostęp do ważnych zasobów serwisu i w efekcie uniemożliwić Googlebotowi dostęp do treści kluczowych dla pozycjonowania.
Podczas ładowania priorytetem powinna być struktura HTML, pozwalająca na “zbudowanie strony” oraz jej treść. Dalej w kolejce znajdują się grafiki, które to najczęściej mają największy wpływ na ilość danych pobieranych do wczytania witryny. Zastosowanie lazy loadingu pozwala renderować w pierwszej kolejne elementy widoczne na ekranie, pozwalając na późniejsze wczytanie fragmentów dostępnych po scrollowaniu niżej.
Tytuły, opisy…
Bez optymalizacji tytułów i opisów nie da się robić skutecznego seo. W przypadku stron typu Single Page App, opartych na frameworkach typu React, Ember czy Angular, warto zatem rozważyć dodanie modułu lub biblioteki, pozwalających na dowolną modyfikację wspomnianych tagów. W przypadku aplikacji zbudowanych na React, najczęściej wybieraną biblioteką jest React Router oraz React Helmet. Coraz większą popularnością cieszy się także oparty na Reactcie, framework Gatsby.
Testowanie i rozwiązywanie problemów z pozycjonowaniem aplikacji JavaScript
Pozycjonowanie stron opartych o Javascript przez wiele lat nie było możliwe. Wypracowanie metod pozwalających dostarczenie treści robotom sieciowym zazębia się z poprawieniem możliwości Google w zakresie renderowania i odczytywania witryn JS. Wciąż jednak istnieje spore ryzyko wystąpienia błędów podczas indeksowania treści naszego serwisu – rozwiązanie dostarczone przez Google nie jest idealne.
Gwarantem pojawienia się w SERP-ach jest umożliwienie dostępu do witryny robotom Google oraz kontrola wyświetlanej przez nich zawartości. W tym celu warto nie ograniczać się w zakresie testowania witryny, zwłaszcza z pomocą wskazanych wcześniej narzędzi od Google.
Dynamiczne renderowanie – gotowiec dla Googlebota
W ramach poprawiania relacji Googlebota z JavaScriptem, Google w swojej dokumentacji sugeruje stosowanie różnych tricków, pozwalających na lepsze przetwarzanie kodu JS. Jednym z nich jest renderowanie dynamiczne.
Renderowanie dynamiczne opiera się na identyfikacji klienta (np. przeglądarki lub robota sieciowego) i dostarczeniu mu odpowiedzi dostosowanej do jego możliwości technicznych. W praktyce, gdy zapytanie zostanie wykonane przez użytkownika (przeglądarkę internetową), strona zostanie wyrenderowana w normalny sposób – pobrany zostanie plik HTML, a pożądana treść zostanie zaciągnięta z bazy z pomocą żądania wysłanego przez skrypt JS. W sytuacji, gdy o dany URL zapyta Googlebot, serwer wyśle w odpowiedzi render strony, zawierający statyczny HTML, który umożliwi szybszą indeksację jego zawartości.
Do wdrożenia dynamicznego renderowania wykorzystać można API o nazwie Rendertron, które działa jako samodzielny serwer HTTP. Renderuje on zawartości adresów URL w sposób czytelny dla botów które nie wykonują poprawnie JavaScriptu. Rendertron pozwala na zapisanie wyrenderowanego pliku w pamięci podręcznej, co znacznie przyspiesza wysyłanie odpowiedzi do bota. Dane w cache będą się aktualizować automatycznie, w określonych przez nas odstępach czasowych.
Pre-renderowane dokumenty są także przydatne z punktu widzenia innych klientów – pozwalają przygotować treści odpowiednie dla czytników z których korzystają osoby niewidzące.
Pozycjonowanie stron a JavaScript – podsumowanie
Rosnący nacisk na prędkość serwowania treści z pewnością zaowocuje dalszym wzrostem popularności języka JavaScript. Google również bierze to pod uwagę i nieustannie pracuje nad poprawieniem indeksowania treści dostępnych z pomoca JS. Odpowiednia optymalizacja i zastosowanie rozwiązań przyjaznym botom to klucz do wysokich pozycji w wynikach wyszukiwania, nawet dla Single Page App oraz innych witryn, bazujących na JS.
Najczęstsze pytania dotyczące pozycjonowania i JavaScript
JavaScript sam w sobie nie jest zły i daje ogromne możliwości w budowaniu nowoczesnych witryn. Problem pojawia się jednak wtedy, gdy jest wdrażany w sposób nieprzemyślany. Całkowite oparcie strony na generowaniu treści po stronie użytkownika (Client-Side Rendering) może stanowić poważną barierę dla robotów wyszukiwarki.
W przeciwieństwie do zwykłych stron HTML, Google stosuje tu dwuetapowe indeksowanie (Two-Wave Indexing). W pierwszej fali robot (Googlebot) pobiera tylko podstawowy, statyczny kod HTML. Dopiero w drugiej fali (która może nastąpić po kilku dniach lub tygodniach z powodu ograniczonych zasobów) strona trafia do kolejki renderowania (WRS), gdzie uruchamiane są skrypty JS i pobierane docelowe treści.
Największym ryzykiem jest tzw. „pusta strona” dla robotów w pierwszej fazie indeksowania – niewidoczne mogą być kluczowe teksty, metatagi (Title, Description) oraz nagłówki. Kolejnym ogromnym problemem jest nawigacja. Jeśli linki wewnętrzne są obsługiwane wyłącznie przez zdarzenia w JS (np. onclick), Google ich nie podąży; roboty wymagają standardowych znaczników a href.
Renderowanie po stronie serwera (SSR) to obecnie jedna z najbardziej zalecanych praktyk. Polega ona na tym, że skrypty są przetwarzane bezpośrednio na serwerze, a do przeglądarki użytkownika (i robotów wyszukiwarki) wysyłany jest już gotowy, w pełni wyrenderowany dokument HTML. Dzięki temu boty widzą całą zawartość natychmiast.
Alternatywą jest wdrożenie tzw. Dynamic Renderingu (renderowania dynamicznego). Mechanizm ten rozpoznaje, kto odwiedza stronę (tzw. User-Agent). Zwykli użytkownicy otrzymują pełną, dynamiczną wersję strony z kodem JavaScript, natomiast po wykryciu robota wyszukiwarki (np. Googlebota), serwer generuje i wysyła mu gotową, statyczną i „lekką” wersję HTML, co gwarantuje bezproblemowe indeksowanie.
Podsumowanie
W powyższym artykule poruszone zostały tematy:
- teoretyczne podstawy JavaScript,
- Google a indeksowanie JavaScript,
- co Google rozpoznaje na stronach JavaScript,
- jak pozycjonować strony oparte na JavaScript.







